Le Concept
Réalisation d’une bande-annonce cinématographique via un pipeline entièrement automatisé sous ComfyUI. L’objectif était de créer un système capable de générer des centaines de séquences cohérentes, de la pré-production au rendu final.
Réalisation d’une bande-annonce cinématographique via un pipeline entièrement automatisé sous ComfyUI. L’objectif était de créer un système capable de générer des centaines de séquences cohérentes, de la pré-production au rendu final.
ComfyUI | Flux.1 | LTX 2.3 | Qwen | ElevenLabs | DaVinci Resolve | Suno |Gemma 3
PRESS PLAY
L’enjeu majeur de ce projet était de supprimer la barrière de la saisie manuelle pour permettre une génération de masse tout en garantissant une cohérence narrative et visuelle entre des centaines de plans.
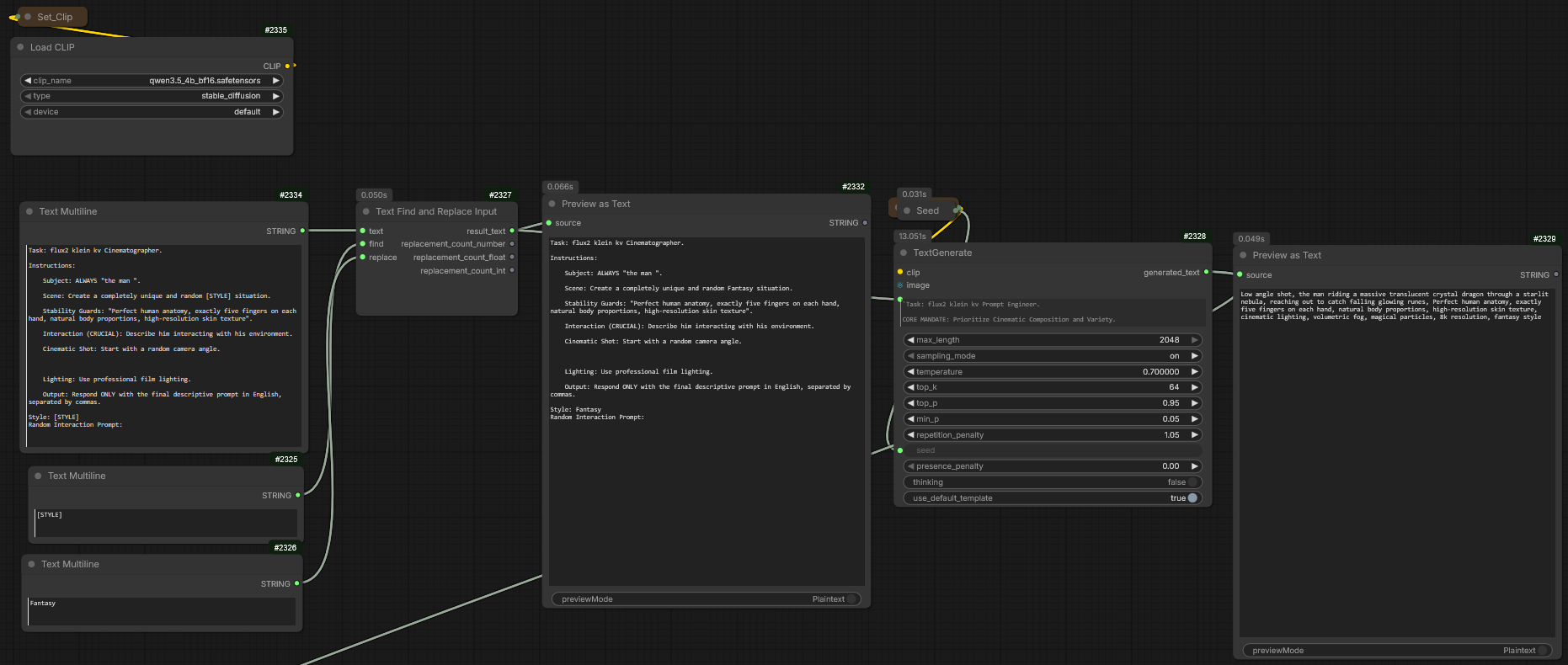
Au lieu d’utiliser un prompt statique, j’ai conçu un système d’agents LLM interconnectés au sein de ComfyUI :
Rôle de Gemma 3 (Scénariste) : Ce modèle agit comme le cerveau narratif. Il reçoit les instructions globales du court-métrage (script, ambiance, enjeux) et décline les séquences en actions logiques.
Rôle de Qwen 2.5/VL (Expert Visuel) : Ce modèle intervient pour traduire les intentions narratives en descriptions techniques optimisées pour les modèles d’images. Il intègre dynamiquement les références du personnage (Character Consistency) pour s’assurer que chaque prompt généré inclut les traits physiques et vestimentaires immuables du protagoniste.
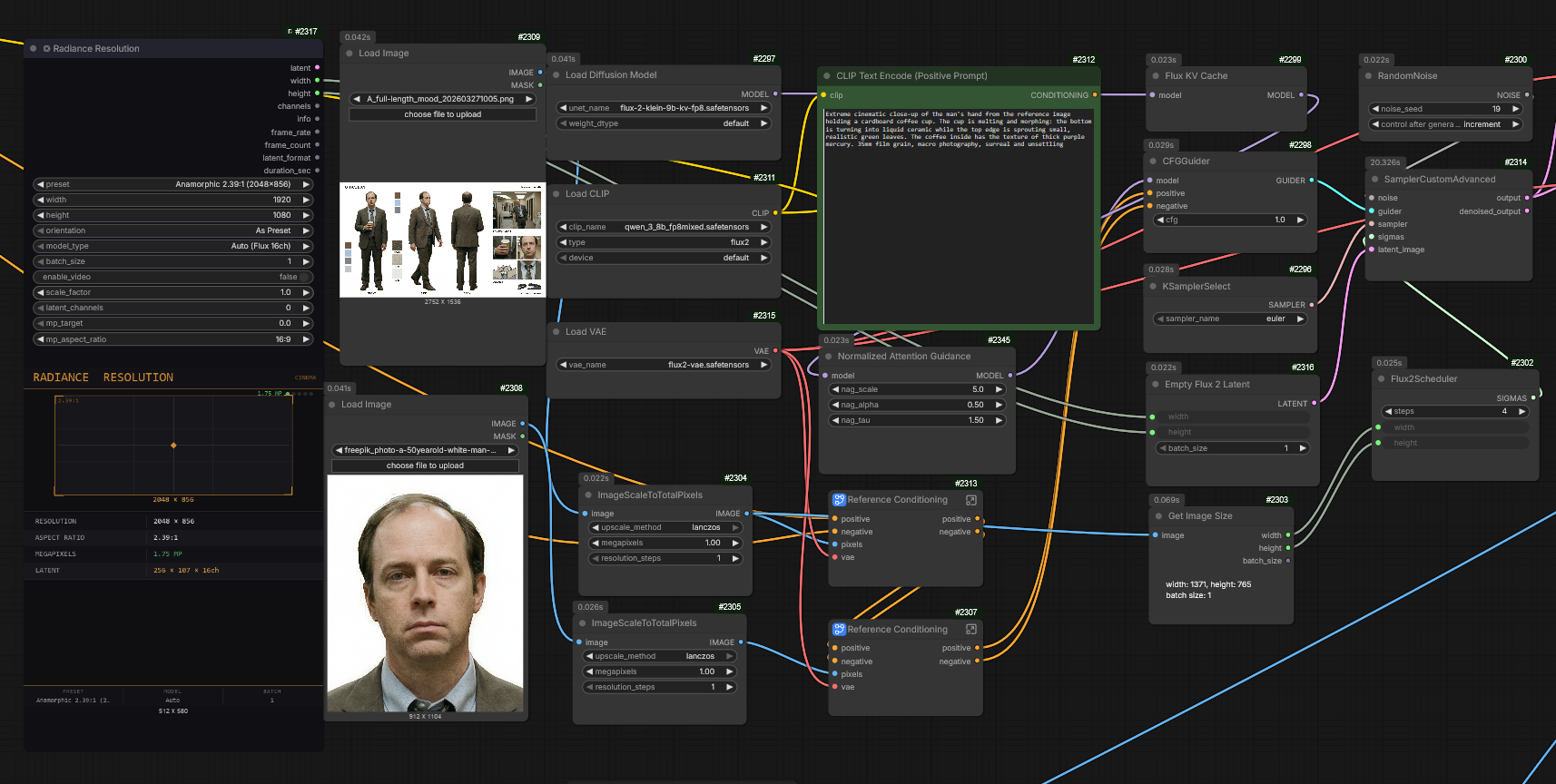
Comme on peut le voir sur le workflow ComfyUI :
Input de Référence : Le système pioche dans une base de données de « Character Sheets » préalablement générées.
Contextualisation : Le LLM reçoit une variable de situation (ex: « le personnage court dans une forêt la nuit »).
Expansion de Prompt : L’agent génère un bloc de texte structuré incluant :
Sujet : Le personnage avec ses attributs fixes.
Action : Description précise du mouvement.
Environnement : Détails sur le décor et l’atmosphère.
Paramètres Techniques : Instructions de lumière et de caméra (ex: « cinematic lighting, anamorphic lens flare »).
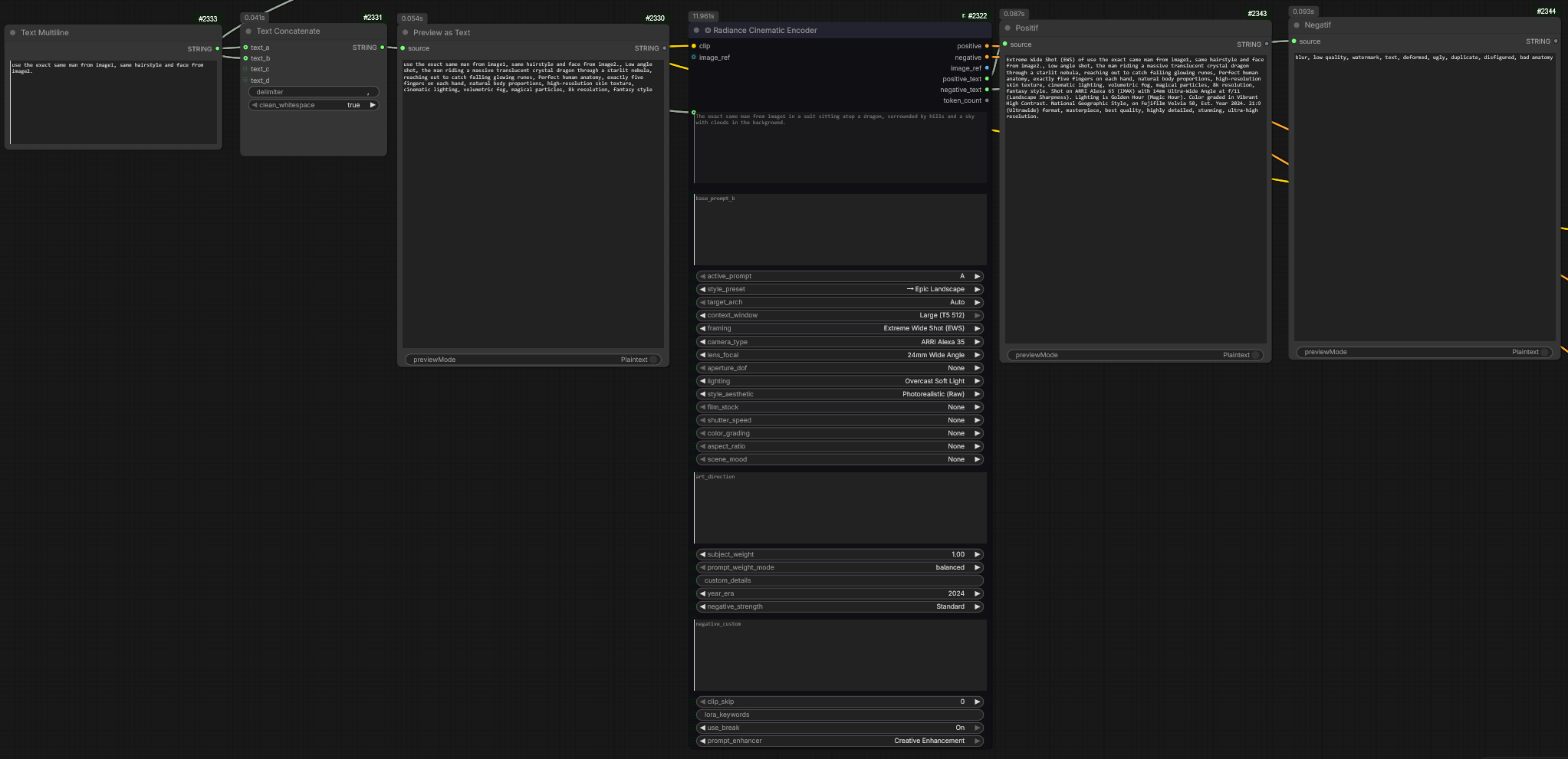
Une fois le prompt narratif généré par les agents LLM, le système doit traduire ces intentions en paramètres techniques de prise de vue. Cette étape est assurée par l’intégration du Radiance Cinematic Encoder.
Pour garantir que le protagoniste ne change pas d’un plan à l’autre, j’ai automatisé l’injection de directives de référence. Le prompt récupéré des étapes précédentes est enrichi d’une instruction de « fixation » :
« Use the exact same man from image1, same hairstyle and face from image2 »
Cette syntaxe force l’encodeur à prioriser les caractéristiques physiques stockées dans les buffers d’images de référence, assurant une continuité visuelle (Consistency) parfaite sur l’ensemble du court-métrage.
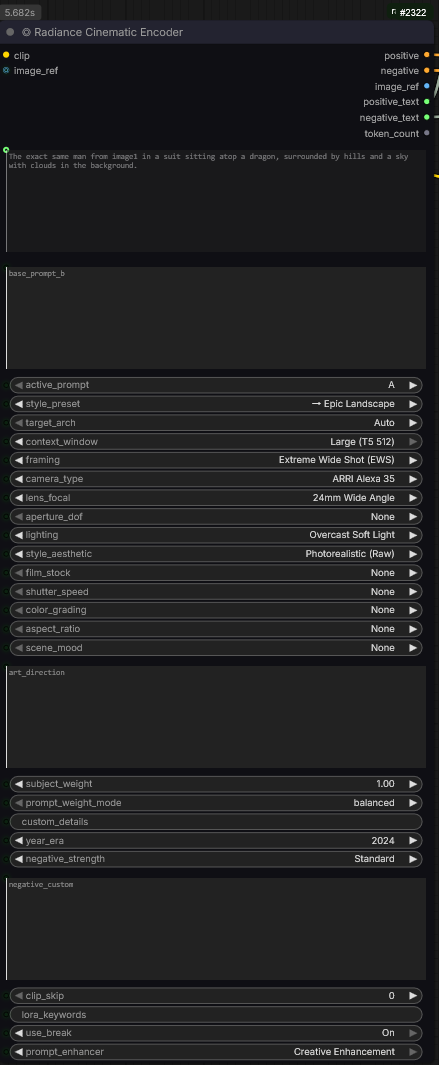
Le texte ainsi enrichi est envoyé dans l’encodeur Radiance. Ce module agit comme un directeur de la photographie virtuel. Il analyse le prompt pour déterminer et « verrouiller » les paramètres suivants :
Angle de caméra : (ex: Low angle, Eye level, Bird’s eye view).
Objectif & Optique (Lens) : Simulation de focales réelles (ex: 35mm pour le récit, 85mm pour les portraits, anamorphique pour le look cinéma).
Style Visuel : Définition du grain, du contraste et de la texture de l’image (ex: Kodak 5219, Teal & Orange, Noir et blanc).
Éclairage (Lighting) : Gestion des sources lumineuses (ex: Rembrandt lighting, Volumetric fog, Backlit).
Le Radiance Cinematic Encoder ne se contente pas de traiter l’image, il « ré-écrit » deux flux de données ultra-optimisés :
Prompt Positif Final : Une version augmentée du texte original, truffée de mots-clés techniques que le modèle Flux.2 [Klein] interprète avec une précision chirurgicale.
Prompt Négatif Final : Une liste d’exclusions générée spécifiquement pour l’angle et le style choisis, afin d’éliminer les aberrations chromatiques, les distorsions de lentille non voulues ou les défauts de composition.
Prompt Positif Final :
Extreme Wide Shot (EWS) of use the exact same man from image1, same hairstyle and face from image2., Low angle shot, the man riding a massive translucent crystal dragon through a starlit nebula, reaching out to catch falling glowing runes, Perfect human anatomy, exactly five fingers on each hand, natural body proportions, high-resolution skin texture, cinematic lighting, volumetric fog, magical particles, 8k resolution, fantasy style. Shot on ARRI Alexa 65 (IMAX) with 14mm Ultra-Wide Angle at f/11 (Landscape Sharpness). Lighting is Golden Hour (Magic Hour). Color graded in Vibrant High Contrast. National Geographic Style, on Fujifilm Velvia 50, Est. Year 2024. 21:9 (Ultrawide) format, masterpiece, best quality, highly detailed, stunning, ultra-high resolution.
Prompt Négatif Final : blur, low quality, watermark, text, deformed, ugly, duplicate, disfigured, bad anatomy
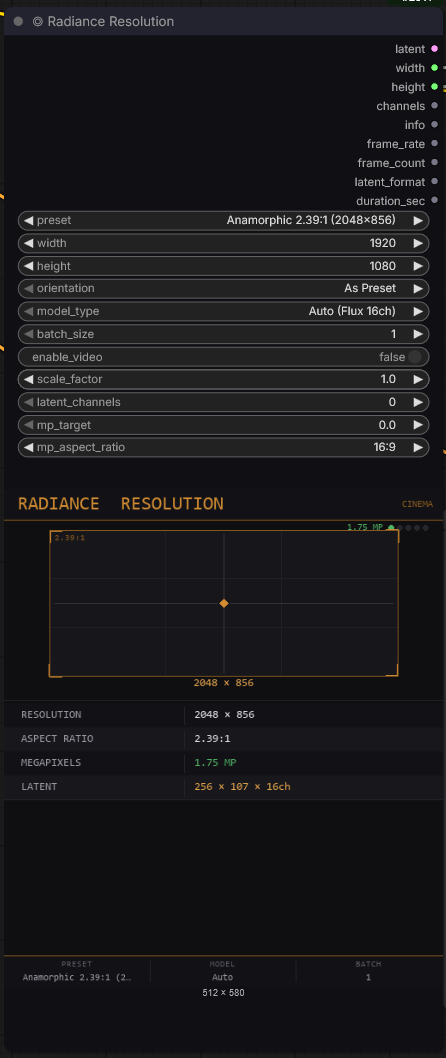
Avant la génération, j’utilise le node Radiance Resolution pour définir l’aspect physique de l’image.
Ratio Anamorphique (2.39:1) : Plutôt que de générer en 16:9 standard, j’ai opté pour le format Cinemascope. Ce choix n’est pas seulement esthétique : il influence la composition spatiale du modèle Flux, le forçant à organiser les éléments de décor sur une largeur plus importante.
Optimisation des Latents : Le node calcule automatiquement la résolution optimale (ex: 2048 x 856) pour exploiter au mieux les 1.75 mégapixels du modèle sans distorsion de l’image.
Comme on le voit sur le node de génération Flux.2 Klein, le système reçoit trois flux critiques :
Les Prompts Dynamiques : Les textes positif et négatif issus de l’encodeur Radiance.
Référence Personnage (Double Input) : J’injecte deux images sources de mon protagoniste. L’utilisation d’un double input permet à l’IA de mieux comprendre les volumes du visage et la texture des cheveux sous différents angles, garantissant une ressemblance constante d’un plan à l’autre.
Normalized Attention Guidance (NAG) : J’ai intégré ce node pour affiner la réponse du modèle aux détails complexes (visage, mains, textures de vêtements), évitant ainsi le lissage excessif.
Le processus de rendu utilise un SamplerCustomAdvanced couplé à un Flux2Scheduler. Cette configuration me permet de contrôler :
La précision du « Denoise » : Pour obtenir une image nette dès le premier jet.
Le CFG Glider : Pour ajuster la fidélité au prompt en temps réel, permettant au modèle d’être créatif sur les arrières-plans tout en restant strict sur les caractéristiques du personnage.
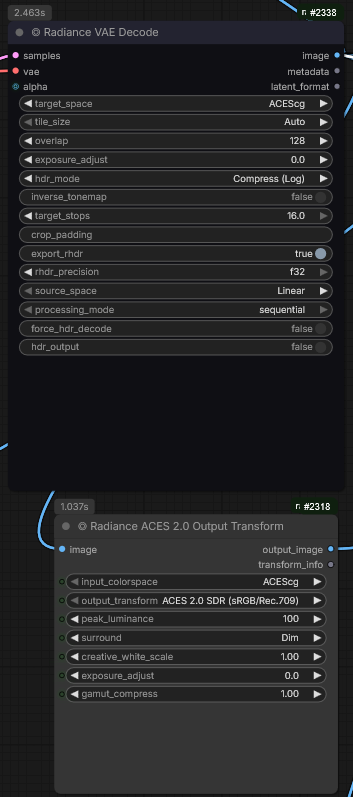
La gestion de la couleur est l’un des piliers de ce workflow. Pour éviter toute dégradation de l’image (clipping) et assurer une intégration parfaite en post-production, j’ai mis en place un pipeline OCIO (OpenColorIO) complet au sein de ComfyUI.
Comme le montre le node VAEDecode (Tiled), je récupère les données latentes pour les transformer en image pixel.
Précision 32-bit : L’utilisation d’un décodeur haute précision permet de conserver toutes les nuances de lumière et de détails dans les zones très sombres ou très brillantes (les hautes lumières).
Tiling : Cette méthode permet de traiter des résolutions très élevées (pour le format anamorphique) sans saturer la mémoire VRAM de la carte graphique.
Le workflow sépare l’affichage de la donnée brute :
Le Flux de Production (ACEScg) : L’image est encodée en ACEScg, le standard de l’industrie pour les effets visuels (VFX). C’est ce flux qui est utilisé pour l’export final en EXR 32-bit, permettant de garder une « latitude » maximale pour l’étalonnage.
Le Flux de Visualisation (OCIO Transform) : Comme l’ACEScg est un espace de travail linéaire non destiné à être vu directement sur un écran standard, j’utilise un node OCIO Display Transform. Il applique une courbe de visualisation (généralement Rec.709 ou sRGB) pour que je puisse juger les couleurs et le contraste avec précision pendant la génération.
Le résultat final est sauvegardé via un node d’enregistrement d’image optimisé pour les fichiers .exr.
Avantage : Contrairement au JPEG ou au PNG, l’EXR ne « brûle » pas les informations. Si une zone du visage semble trop sombre dans ComfyUI, je peux la récupérer sans perte de qualité dans DaVinci Resolve grâce à la profondeur de bits du fichier.
Pour passer de l’image fixe à la vidéo, le système doit comprendre ce qu’il a créé afin de définir un mouvement cohérent. Cette étape d’interprétation visuelle est confiée à Qwen 2.5/VL (Vision-Language Model).
L’image haute définition (ton personnage sur le dragon de cristal) est renvoyée dans le modèle Qwen. Grâce à ses capacités multimodales, le modèle effectue une lecture détaillée de la scène :
Identification des éléments : Il reconnaît le personnage, sa posture, le dragon et l’environnement spatial.
Déduction de l’Action : Plutôt que d’appliquer un mouvement générique, Qwen déduit une action pertinente par rapport à la composition (ex: « Le dragon bat des ailes tandis que l’homme lève sa main droite pour invoquer de l’énergie »).
Comme on le voit sur ton node TextGenerate, Qwen rédige un nouveau prompt spécifiquement optimisé pour la vidéo :
Focus sur la dynamique : Il décrit les fluides, les particules et les micro-mouvements des vêtements.
Mouvement de Caméra : Il ajoute des instructions de travelling ou de zoom lent pour renforcer l’aspect cinématographique du plan.
Maintien de l’esthétique : Il réaffirme les codes stylistiques (ex: « 90s retro tech aesthetic, photorealistic ») pour que le modèle vidéo ne dévie pas de la « First Frame ».
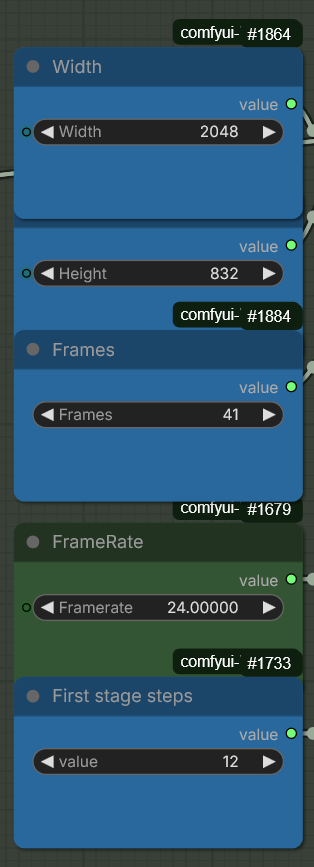
Le contrôle du rendu vidéo est défini par des variables strictes pour assurer la fluidité cinématographique :
Résolution & Ratio : Alignement sur le format anamorphique (2048 x 832) pour une cohérence parfaite avec l’image source.
Temporalité : Génération de 41 frames à un framerate de 24.0 fps, respectant le standard du cinéma pour éviter l’aspect « vidéo numérique » trop fluide.
Sampling en deux étapes : Utilisation de 12 étapes pour le « First stage steps », permettant de dégrossir le mouvement avant d’affiner les détails.
L’intégration du système Clownshark apporte une robustesse supplémentaire au modèle LTX 2.3 :
Conditionnement Image-to-Video : La « First Frame » (le personnage sur le dragon) sert de point d’ancrage absolu. Le workflow Clownshark excelle dans le maintien de la cohérence des détails complexes (comme les reflets sur le cristal du dragon) pendant l’animation.
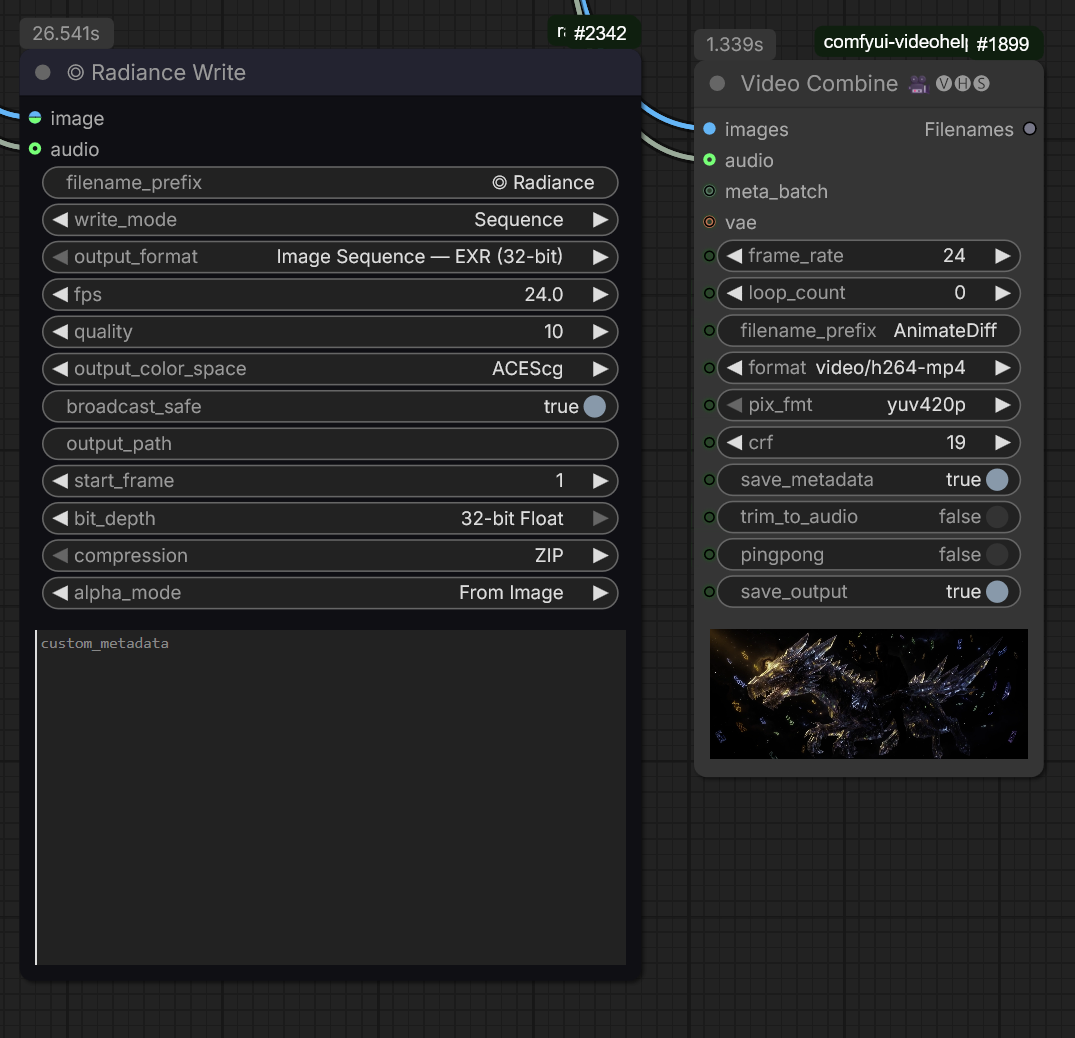
Le node Radiance Write est configuré pour générer le « Master » de la séquence :
Format Image Sequence – EXR (32-bit) : Ce format de fichier non compressé (ZIP) préserve l’intégralité des données lumineuses générées par l’IA.
Espace Colorimétrique ACEScg : L’export est verrouillé en ACEScg pour garantir une cohérence parfaite lors de l’importation dans DaVinci Resolve ou After Effects.
Profondeur 32-bit Float : Cette précision permet de manipuler l’exposition et la colorimétrie en post-production sans jamais voir apparaître d’artefacts de compression ou de « banding » dans les dégradés du ciel ou les effets de particules.
Parallèlement, le node Video Combine génère une version légère de la séquence :
Format MP4 (h264) : Un fichier compressé, idéal pour une lecture fluide et instantanée.
Utilité : Cette vidéo de preview permet de valider rapidement le mouvement, le rythme et la cohérence globale du plan sans avoir à charger les fichiers EXR très lourds. Elle sert également de référence pour le montage « offline » avant le conformage final.
Scalabilité : Automatisation permettant de produire un volume massif de plans.
Fidélité Technique : Workflow respectant les standards de l’industrie cinématographique (ACES CG).
Direction Globale : Supervision de chaque étape, du prompt engineering à l’assemblage final.